

Category
Sub Category
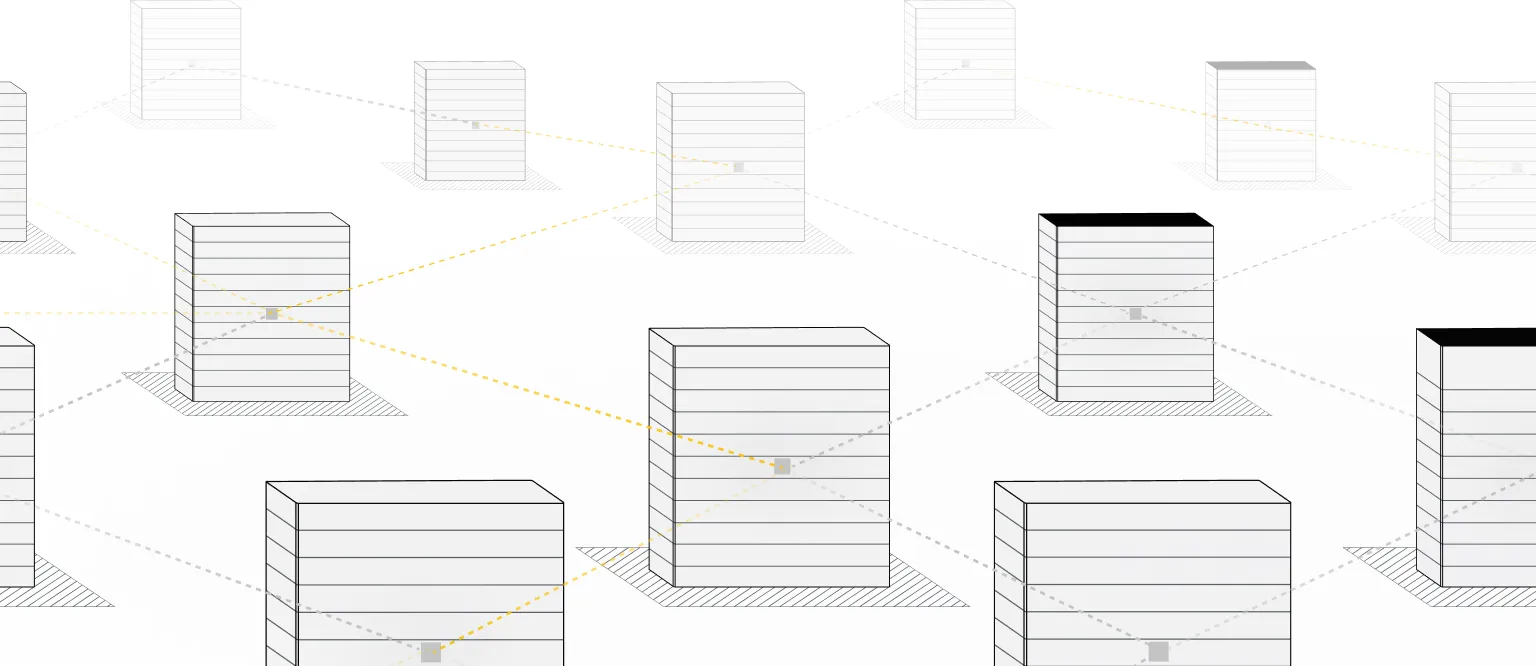
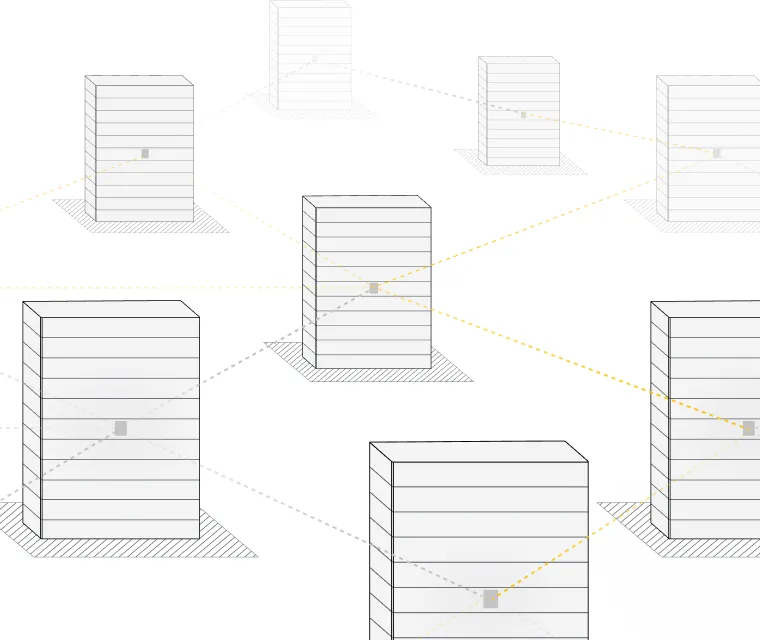
Scale-Up: SkyHammer
Rack-Scale Performance.
Open by Design.
Unifies distributed GPU clusters into a single, memory-coherent system, delivering a lossless, deterministic fabric with bounded tail latency using open standards
Jan 30, 2026
Author



.svg)
.svg)